

When Microsoft 365 went down for nearly 10 hours on January 22, 2026, millions of users found themselves unable to send emails, join Teams meetings, or access critical business tools. The outage, which Microsoft blamed on "a portion of dependent service infrastructure in the North America region isn't processing traffic as expected," served as a stark reminder of our reliance on cloud services and how quickly technology disruptions can impact daily operations. But what actually happens during a technology outage? How do these disruptions occur, and what processes do companies use to detect and fix them?
Inside the Microsoft 365 Outage: What Went Wrong
The January 2026 Microsoft outage wasn't just a minor inconvenience—it was a significant disruption that affected thousands of businesses and individuals across North America. According to Downdetector, a service that tracks website and app outages, complaints spiked at around 3 p.m. ET with approximately 16,000 people reporting issues accessing Microsoft 365 services. The problems persisted through the evening, with users experiencing errors when trying to send or receive emails through Outlook, access SharePoint Online, or use Microsoft Defender security tools.

Microsoft's status page indicated the root cause was infrastructure in North America that "isn't processing traffic as expected." The company stated it was "carefully rebalancing traffic across all affected infrastructure in the region" and working to restore services. Impacted users reported receiving "451 4.3.2 temporary server issue" error messages when attempting to send or receive email through Outlook. Other affected services included Exchange Online, SharePoint Online searches, Microsoft Purview, and the Microsoft 365 admin center.
Timeline: How the Microsoft Outage Developed Over 10 Hours
The Microsoft 365 disruption followed a familiar pattern for major technology outages: initial reports, acknowledgment, investigation, mitigation attempts, and eventual resolution. The timeline began on Thursday afternoon, January 22, when users first started reporting issues. By 3 p.m. ET, Downdetector showed a significant spike in outage reports. Microsoft acknowledged the problem on its service health dashboard, stating users "may be seeing degraded service functionality or be unable to access multiple Microsoft 365 services."
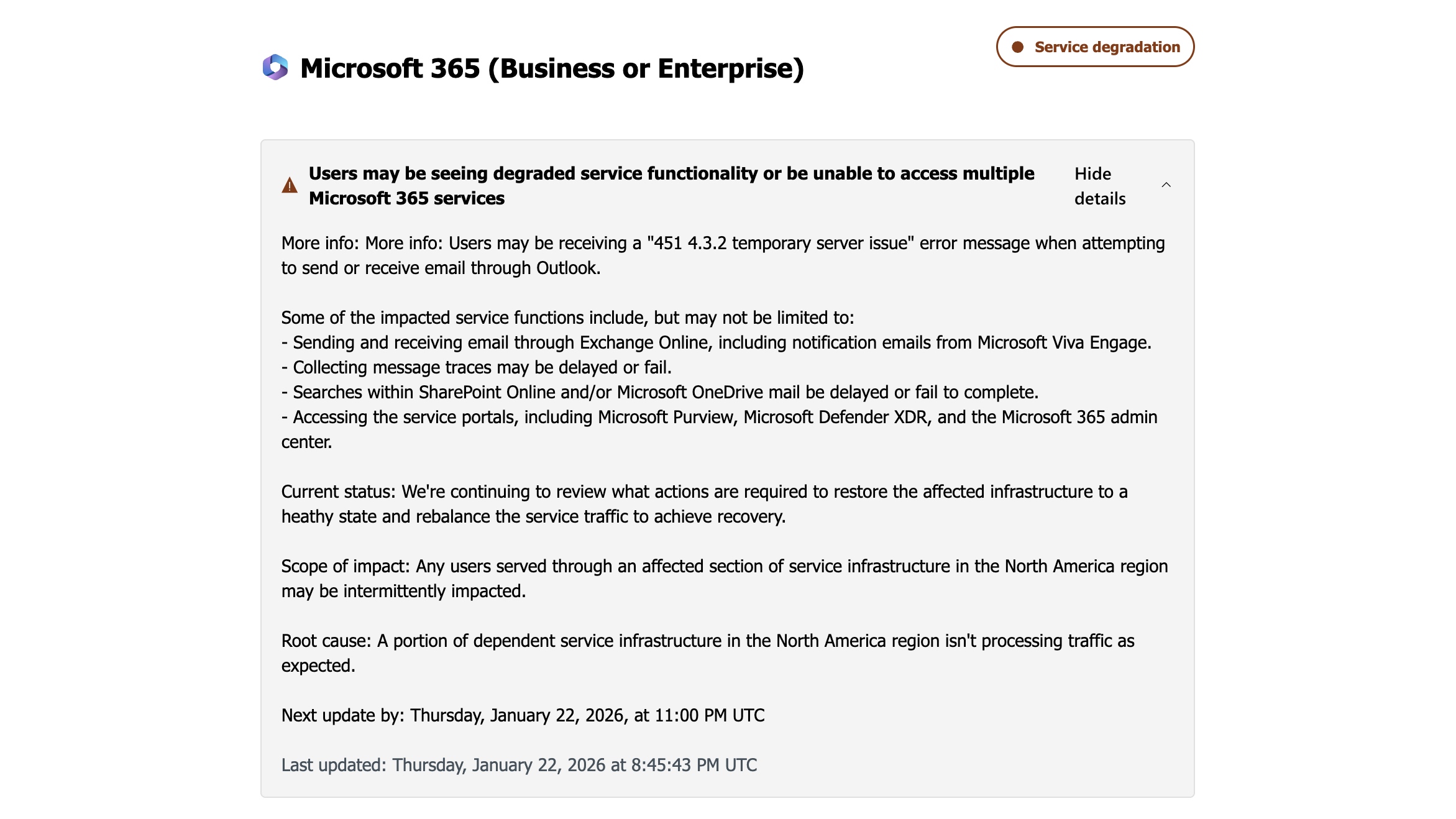
At 4:14 p.m. ET, Microsoft posted on X that it had "restored the affected infrastructure to a healthy state," but later clarified it was still "rebalancing traffic across all affected infrastructure to ensure the environment enters into a balanced state." As the evening progressed, the company continued working on the issue, with updates coming through its MO1221364 communication reference. By approximately 1:30 a.m. ET on Friday, Microsoft confirmed "impact has been resolved," marking nearly 10 hours of disruption for affected users.
Why Technology Outages Happen: Common Causes and Triggers
Technology outages like Microsoft's January 2026 disruption don't occur in isolation—they're typically the result of specific failures within complex systems. According to cloud infrastructure experts, several common causes can trigger service disruptions. Human error remains a significant factor, whether through incorrect configuration changes, software updates with unintended consequences, or operational mistakes. The 2024 CrowdStrike antivirus software update that caused global Microsoft 365 outages serves as a recent example of how a single update can have cascading effects.
Technical problems represent another major category of outage causes. These can include hardware failures in data centers, software bugs that surface under specific conditions, network connectivity issues between service components, or capacity limitations when traffic spikes beyond expected levels. Microsoft's reference to "a portion of dependent service infrastructure in the North America region isn't processing traffic as expected" suggests either a hardware failure, software issue, or capacity problem within their infrastructure.
Cyber attacks represent an increasing threat to service availability, with distributed denial-of-service (DDoS) attacks overwhelming systems with traffic or ransomware attacks encrypting critical infrastructure. Environmental factors like power outages, cooling system failures in data centers, or natural disasters can also disrupt physical infrastructure. Finally, routine maintenance or upgrades can sometimes trigger unexpected issues, especially when complex dependencies exist between system components.
How Companies Detect and Fix Outages: The Monitoring Ecosystem
When services go down, how do companies know—and how do they fix them? Modern technology providers employ sophisticated monitoring systems that continuously check service health from multiple perspectives. Microsoft, for instance, uses real-time telemetry to spot and restore network device outages internally. As described in their Inside Track Blog, "Through real-time telemetry, network engineers can isolate and remediate issues in minutes—not hours—to keep their colleagues productive and our services running smoothly."
Third-party monitoring services like Downdetector play a crucial role in outage detection by aggregating user reports from across the internet. These services help companies understand the scope and impact of disruptions faster than internal monitoring alone might indicate. Downdetector's methodology includes analyzing user-submitted problem reports, social media mentions, and automated checks to create a comprehensive view of service availability.
Once an outage is detected, companies follow incident response protocols that typically involve: 1) Acknowledging the issue through status pages and communications, 2) Assembling response teams with relevant expertise, 3) Investigating root causes through log analysis and system diagnostics, 4) Implementing fixes or workarounds, 5) Monitoring recovery, and 6) Conducting post-mortem analyses to prevent recurrence. The goal is to minimize what's known as Mean Time to Repair (MTTR), with leading companies aiming to resolve issues in minutes rather than hours.
Where Things Stand Now: Latest on Technology Outage Management
Following the January 2026 outage, Microsoft has fully restored services and continues to monitor systems for any residual issues. The company's communication reference MO1221364 provides closure details for administrators tracking the incident. For users, the immediate crisis has passed, but the event highlights ongoing challenges in maintaining always-available cloud services.
The technology industry continues to evolve its approach to outage prevention and management. Advances in artificial intelligence and machine learning are being applied to predict potential failures before they occur by analyzing patterns in system behavior. Automated remediation systems can sometimes fix issues without human intervention, while improved redundancy designs help ensure single points of failure don't cascade into widespread outages.
User awareness has also increased, with more individuals and businesses understanding the importance of having contingency plans when critical services become unavailable. The proliferation of status pages, outage notification services, and transparent communication from technology providers represents progress in how outages are managed from a user perspective.
What Happens Next: Preparing for Future Technology Disruptions
While technology outages are inevitable in complex systems, their impact can be mitigated through proper preparation and response strategies. For businesses relying on cloud services like Microsoft 365, experts recommend several key practices: First, maintain alternative communication channels (like phone trees or secondary email providers) for critical operations. Second, regularly back up important data to multiple locations, including offline storage. Third, familiarize teams with service status pages and outage notification systems.
For individual users, understanding basic troubleshooting steps can help during outages: checking service status pages first before assuming local issues, trying alternative access methods (like mobile apps if web interfaces fail), and being patient as companies work through resolution processes. It's also wise to have important documents available locally rather than solely in cloud storage.
Technology providers continue investing in resilience improvements, including geographic redundancy (distributing services across multiple data center regions), circuit-breaking patterns (isolating failing components to prevent cascading failures), and chaos engineering (intentionally breaking systems in controlled environments to identify weaknesses). These approaches aim to make services more robust while acknowledging that perfect availability remains an aspirational goal rather than an achievable reality.
The Bottom Line: Key Points to Remember About Technology Outages
Technology outages like Microsoft's January 2026 disruption teach valuable lessons about our interconnected digital world. First, understand that outages are inevitable in complex systems—even with massive investments in reliability. Second, recognize the common causes: human error, technical failures, cyber attacks, and environmental factors. Third, appreciate the sophisticated monitoring and response systems companies use to detect and fix issues quickly.
For users, the key takeaways are practical: Check status pages first during suspected outages, maintain backup communication methods, and implement redundancy for critical business functions. For technology providers, the ongoing challenge is balancing innovation with stability, transparency with reassurance, and rapid recovery with thorough investigation.
As cloud services become increasingly integral to personal and professional life, understanding how outages work—and how to navigate them—becomes an essential digital literacy skill. The Microsoft 365 outage of January 2026 serves as both a case study in modern service disruption and a reminder that behind every seamless digital experience lies complex infrastructure that occasionally needs repair.
